Trực quan hóa dữ liệu đóng một vai trò quan trọng trong học máy. Được phát triển dựa trên nền tảng của Matplotlib, Yellowbrick là thư viện mở rộng API Scikit-Learn để giúp lựa chọn mô hình và điều chỉnh siêu tham số dễ dàng hơn.
Các tính năng được sử dụng trực quan hóa dữ liệu trong Máy học gồm:
- Điều chỉnh siêu tham số (Hyperparameter)
- Đánh giá hiệu suất mô hình (Model Assumptions)
- Xác thực mô hình giả định
- Thu thập các ngoại lệ
- Lựa chọn các tính năng quan trọng nhất
- Xác định các mẫu, mối tương quan giữa các tính năng

Sử dụng hình ảnh để biểu diễn dữ liệu trong các trường hợp trên trong Máy học được gọi là Trực quan hóa dữ liệu Máy học (Machine Learning Visualizations).
Trực quan hóa dữ liệu trong Máy học đôi khi là một quá trình phức tạp vì nó yêu cầu việc code bằng Python khá nhiều. Tuy nhiên, nhờ thư viện mã nguồn mở Yellowbrick của Python, ngay cả với những hình ảnh Trực quan hóa dữ liệu Máy học phức tạp cũng có thể được tạo với mà không cần phải code nhiều. Là thư viện mở rộng API Scikit-learning, nó cung cấp các tính năng nâng cao xây dựng các biểu đồ trực quan hóa dữ liệu mà Scikit-learning không cung cấp.
Hôm nay, chúng ta sẽ cùng tìm hiểu chi tiết các phương pháp trực quan hóa máy học dưới đây và cách triển khai bằng Yellowbrick.
Yellowbrick — Hãy bắt đầu ngay bây giờ
Cài đặt
Việc cài đặt Yellowbrick có thể được thực hiện bằng cách chạy một trong các lệnh sau.
- trình cài đặt gói pip :
pip install yellowbrick- trình cài đặt gói conda :
conda install -c districtdatalabs yellowbrickSử dụng Yellowbrick
Trình hiển thị Yellowbrick có cú pháp giống như Scikit-learning. Trình hiển thị dữ liệu trực quan là một đối tượng học từ dữ liệu để tạo ra biểu đồ trực quan hóa. Nó thường được sử dụng với công cụ ước tính Scikit-learning. Để đào tạo một trình hiển thị, chúng ta sử dụng một hàm gọi là fit() – [ Ví dụ: visualizer.fit(X, y) # Fit the data to the visualizer ]
Lưu biểu đồ
Để lưu một biểu đồ được tạo bằng trình hiển thị Yellowbrick, chúng tôi gọi phương thức show() như sau. Thao tác này sẽ lưu biểu đồ dưới dạng tệp PNG.
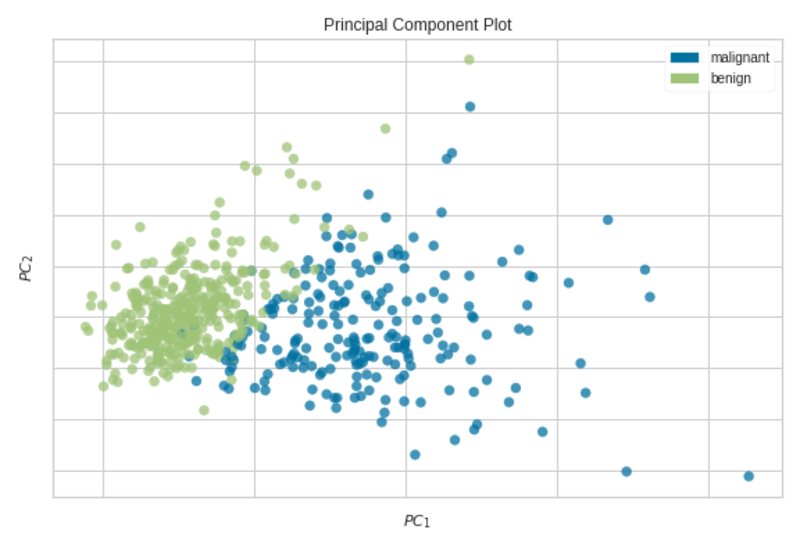
Biểu đồ thành phần chính trực quan hóa dữ liệu chiều cao trong biểu đồ phân tán 2D hoặc 3D. Do đó, biểu đồ này cực kỳ hữu ích để xác định các mẫu quan trọng trong dữ liệu chiều cao.
visualizer.show(outpath="name_of_the_plot.png")Dưới đây là 10 Phương pháp trực quan hóa dữ liệu cho Máy học bạn nên biết bằng Yellowbrick bạn nên biết:
1. Biểu đồ Principal Component
Cách sử dụng
Biểu đồ thành phần chính trực quan hóa dữ liệu chiều cao trong biểu đồ phân tán 2D hoặc 3D. Do đó, biểu đồ này cực kỳ hữu ích để xác định các mẫu quan trọng trong dữ liệu chiều cao.
Triển khai với Yellowbrick
Tạo biểu đồ này bằng phương pháp truyền thống rất phức tạp và tốn thời gian. Trước tiên, chúng ta cần áp dụng PCA cho tập dữ liệu và sau đó sử dụng thư viện matplotlib để tạo biểu đồ phân tán.
Thay vào đó, chúng ta có thể sử dụng lớp trình hiển thị PCA của Yellowbrick để đạt được chức năng tương tự. Nó sử dụng phương pháp phân tích thành phần chính, giảm kích thước của tập dữ liệu và tạo biểu đồ phân tán với 2 hoặc 3 dòng mã! Tất cả những gì chúng ta cần làm là chỉ định một số đối số từ khóa trong lớp PCA().
Hãy lấy một ví dụ để hiểu rõ hơn về điều này. Ở đây, chúng tôi sử dụng bộ dữ liệu breast_cancer (xem phần Trích dẫn ở cuối) có 30 tính năng và 569 mẫu thuộc hai loại (Ác tính và Lành tính). Do dữ liệu có nhiều chiều (30 tính năng), không thể vẽ biểu đồ dữ liệu gốc trong biểu đồ phân tán 2D hoặc 3D trừ khi chúng tôi áp dụng PCA cho tập dữ liệu.
Đoạn mã sau giải thích cách chúng ta có thể sử dụng trình hiển thị PCA của Yellowbrick để tạo biểu đồ phân tán 2D của tập dữ liệu 30 chiều.
projection=3
Sơ đồ thành phần chính — 3D
- scale: bool, mặc định
True. Điều này cho biết liệu dữ liệu có nên được thu nhỏ hay không. Chúng ta nên chia tỷ lệ dữ liệu trước khi chạy PCA. Tìm hiểu thêm về đây . - projection: int, mặc định là 2 khi tạo biểu đồ phân tán 2D và là 3 khi tạo một biểu đồ phân tán 3D.
projection=2projection=3 - classes: danh sách, mặc định là
None. Điều này chỉ ra các nhãn lớp cho mỗi lớp trong y. Tên lớp sẽ là nhãn cho chú giải.
2. Validation Curve
Cách sử dụng
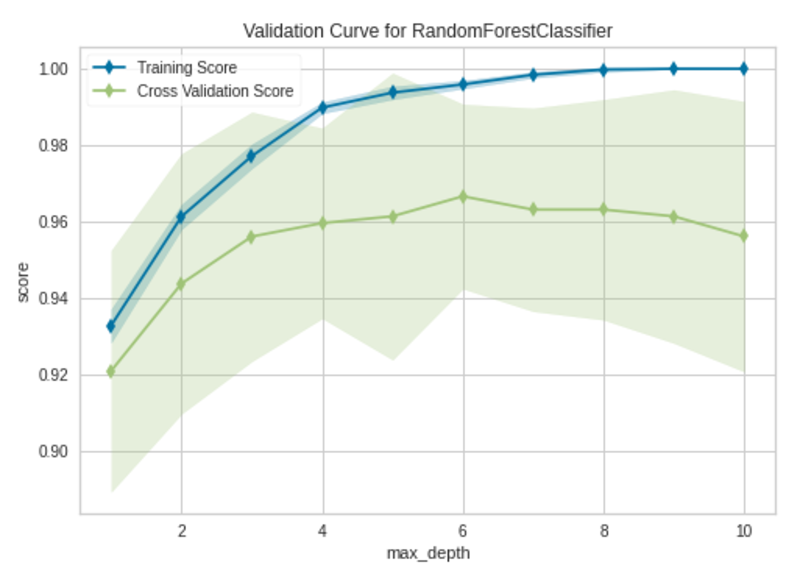
Validation Curve biểu diễn sự ảnh hưởng của một siêu tham số duy nhất đối với tập hợp xác thực và đào tạo. Bằng cách nhìn vào đường cong, chúng ta có thể xác định các điều kiện trang bị thừa, trang bị thiếu và vừa phải của mô hình đối với các giá trị được chỉ định của siêu tham số đã cho. Khi có nhiều siêu tham số để điều chỉnh cùng một lúc, không thể sử dụng đường cong xác thực. Ngay lập tức, bạn có thể sử dụng tìm kiếm dạng lưới hoặc tìm kiếm ngẫu nhiên.
Triển khai với Yellowbrick
Tạo một Validation Curve bằng phương pháp truyền thống rất phức tạp và tốn thời gian. Thay vào đó, chúng ta có thể sử dụng trình hiển thị biểu đồ này ngay trên Yellowbrick.
Để vẽ biểu đồ đường cong xác thực ở Yellowbirck, chúng ta sẽ xây dựng một bộ phân loại rừng ngẫu nhiên bằng cách sử dụng cùng bộ dữ liệu breast_ Cancer (xem phần Trích dẫn ở cuối). Chúng ta sẽ vẽ biểu đồ ảnh hưởng của siêu tham số max_depth trong mô hình rừng ngẫu nhiên.
Đoạn mã sau giải thích cách chúng ta có thể sử dụng trình hiển thị đường cong xác thực của Yellowbrick để tạo đường cong xác nhận bằng cách sử dụng bộ dữ liệu breast_ Cancer.

Đường cong xác thực
Mô hình bắt đầu overfit khi giá trị max_depth lớn hơn 6. Khi mô hình dữ liệu huấn luyện phù hợp, nó giúp trực quan hóa thông tin ẩn của dữ liệu một cách hiệu quả.max_depth=6
Các tham số quan trọng nhất của trình hiển thị ValidationCurve bao gồm:
- estimator: Đây có thể là bất kỳ mô hình ML Scikit-learning nào, chẳng hạn như decision tree, random forest, support vector machine, v.v.
- param_name: Đây là tên của siêu tham số mà chúng ta muốn theo dõi.
- param_range: Bao gồm các giá trị có thể có cho param_name .
- cv: int, xác định số lượng nếp gấp cho xác thực chéo.
- scoring: chuỗi, chứa phương pháp chấm điểm của mô hình. Để phân loại, độ chính xác được ưu tiên.
3. Learning Curve
Cách sử dụng
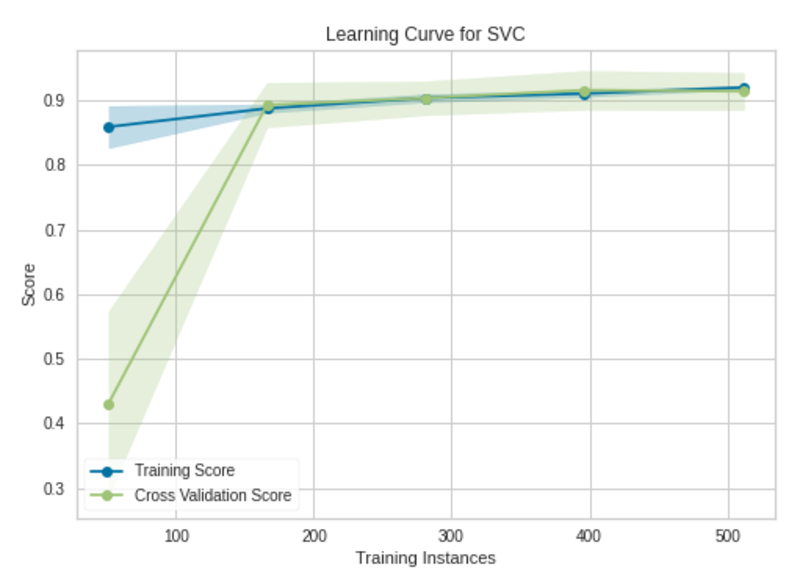
Learning Curve vẽ sơ đồ các lỗi hoặc độ chính xác của quá trình đào tạo và xác thực so với số lượng epochs hoặc số lượng phiên bản đào tạo. Bạn có thể nghĩ rằng cả Learning Curve và xác thực đều giống nhau, nhưng số lần lặp lại được vẽ trong trục x của nó trong khi các giá trị của siêu tham số được vẽ trong trục x của đường cong xác thực.
Nó được sử dụng để:
- Phát hiện các điều kiện underfitting, overfitting và just-right của mô hình.
- Xác định slow convergence, oscillating, oscillating with divergence và proper convergence khi tìm tốc độ học tập tối ưu của mạng thần kinh hoặc mô hình ML.
- Sử dụng để xem mô hình được hưởng lợi bao nhiêu từ việc thêm nhiều dữ liệu đào tạo hơn. Khi được sử dụng theo cách này, trục x hiển thị số lượng phiên bản đào tạo.
Triển khai với Yellowbrick
Tạo đường cong học tập bằng phương pháp truyền thống rất phức tạp và tốn thời gian. Thay vào đó, chúng ta có thể sử dụng trình hiển thị LearningCurve của Yellowbrick.
Để vẽ sơ đồ đường cong học tập ở Yellowbirck, chúng ta sẽ xây dựng một bộ phân loại véc tơ hỗ trợ bằng cách sử dụng cùng bộ dữ liệu breast_ Cancer (xem phần Trích dẫn ở cuối).
Đoạn mã sau giải thích cách chúng ta có thể sử dụng trình hiển thị LearningCurve của Yellowbrick để tạo đường cong xác thực bằng cách sử dụng bộ dữ liệu breast_cancer .
Hình ảnh LearningCurve
Mô hình sẽ không được hưởng lợi từ việc thêm nhiều phiên bản đào tạo. Mô hình đã được đào tạo với 569 trường hợp đào tạo. Độ chính xác xác thực không được cải thiện sau 175 phiên bản đào tạo.
Các tham số quan trọng nhất của trình hiển thị LearningCurve bao gồm:
- estimator: Đây có thể là bất kỳ mô hình ML Scikit-learning nào, chẳng hạn như cây quyết định, rừng ngẫu nhiên, máy vectơ hỗ trợ, v.v.
- cv: int, xác định số lượng nếp gấp cho xác thực chéo.
- scoring: chuỗi, chứa phương pháp chấm điểm của mô hình. Để phân loại, độ chính xác được ưu tiên.
4. Biểu đồ Elbow
Cách sử dụng
Biểu đồ Elbow được sử dụng để chọn số cụm tối ưu trong phân cụm K-Means. Mô hình phù hợp nhất tại điểm mà nó xuất hiện trong biểu đồ đường. Elbow là điểm uốn trên biểu đồ.
Triển khai với Yellowbrick
Tạo biểu đồ Khuỷu tay bằng phương pháp truyền thống rất phức tạp và tốn thời gian. Thay vào đó, chúng ta có thể sử dụng KElbowVisualizer của Yellowbrick.
Để vẽ sơ đồ đường cong học tập trong Yellowbirck, chúng ta sẽ xây dựng mô hình phân cụm K-Means bằng bộ dữ liệu iris (xem phần Trích dẫn ở cuối).
Đoạn mã sau giải thích cách chúng ta có thể sử dụng KElbowVisualizer của Yellowbrick để tạo biểu đồ Elbow bằng cách sử dụng bộ dữ liệu iris.
Hình ảnh biểu đồ Elbow
Elbow xảy ra ở k=4 (được chú thích bằng đường đứt nét). Biểu đồ chỉ ra rằng số cụm tối ưu cho mô hình là 4. Nói cách khác, mô hình phù hợp tốt với 4 cụm.
Các tham số quan trọng nhất của KElbowVisualizer bao gồm:
- estimator: ví dụ mô hình K-Means
- k: int hoặc tuple. Nếu là số nguyên, nó sẽ tính điểm cho các cụm trong khoảng (2, k). Nếu là một bộ, nó sẽ tính điểm cho các cụm trong phạm vi đã cho, ví dụ: (3, 11).
5. Biểu đồ Silhouette
Cách sử dụng
Biểu đồ Silhouette được sử dụng để chọn số cụm tối ưu trong phân cụm K-Means và cũng để phát hiện sự mất cân bằng của cụm. Biểu đồ này cung cấp kết quả rất chính xác so với biểu đồ Elbow.
Triển khai Yellowbrick
Tạo biểu đồ hình bóng bằng phương pháp truyền thống rất phức tạp và tốn thời gian. Thay vào đó, chúng ta có thể sử dụng SilhouetteVisualizer của Yellowbrick.
Để tạo biểu đồ hình bóng trong Yellowbirck, chúng ta sẽ xây dựng mô hình phân cụm K-Means bằng bộ dữ liệu iris (xem phần Trích dẫn ở cuối).
Các khối mã sau đây giải thích cách chúng ta có thể sử dụng SilhouetteVisualizer của Yellowbrick để tạo các biểu đồ bóng bằng cách sử dụng bộ dữ liệu iris với các giá trị k (số lượng cụm) khác nhau.
k=2
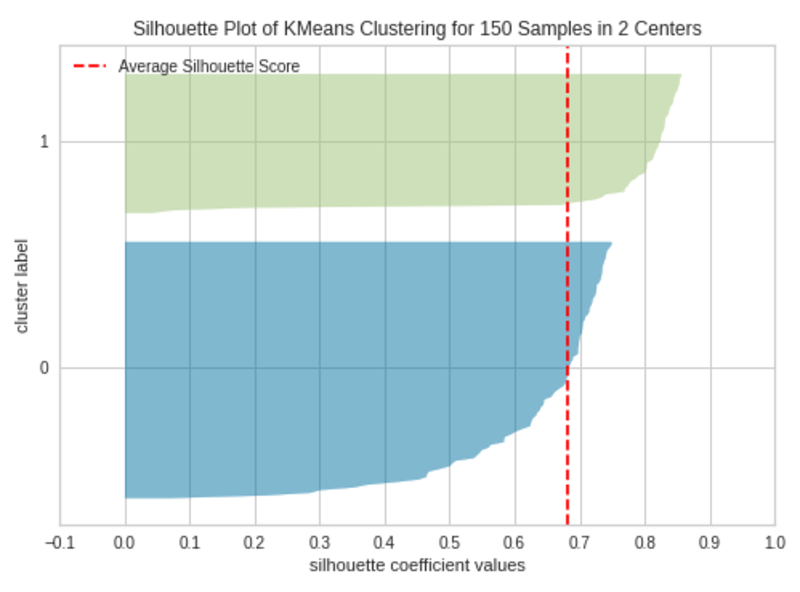
Biểu đồ Silhouette với 2 cụm (k=2)|Hình ảnh của tác giảBằng cách thay đổi số lượng cụm trong lớp KMeans(), chúng ta có thể thực thi đoạn mã trên vào các thời điểm khác nhau để tạo các biểu đồ bóng khi k=3, k=4 và k=5.
k=3
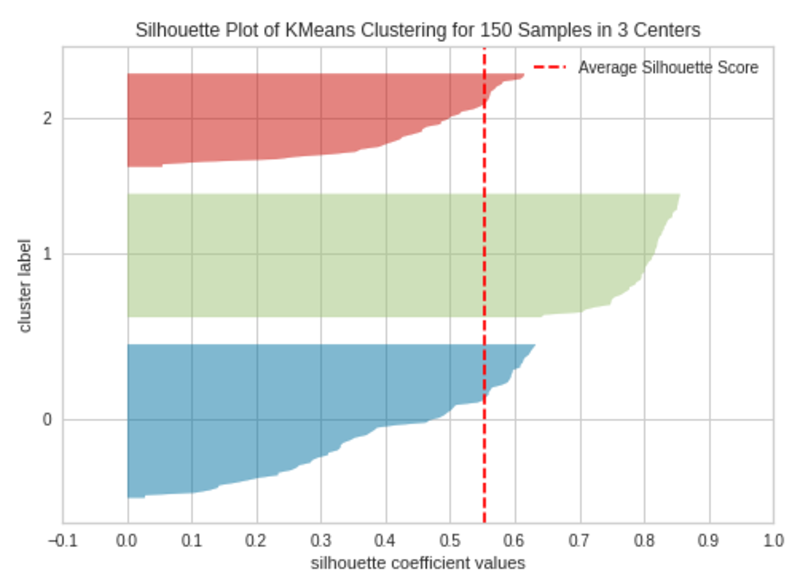
Biểu đồ Silhouette với 3 cụm (k=3)
k=4

Biểu đồ Silhouette với 4 cụm (k=4)
k=5

Biểu đồ Silhouette với 4 cụm (k=5)|Hình ảnh của tác giảBiểu đồ hình bóng chứa một hình con dao trên mỗi cụm. Mỗi hình dao được tạo bởi các thanh đại diện cho tất cả các điểm dữ liệu trong cụm. Vì vậy, chiều rộng của hình con dao biểu thị số lượng tất cả các phiên bản trong cụm. Chiều dài thanh biểu thị Hệ số Silhouette cho từng trường hợp. Đường đứt nét biểu thị điểm bóng – Nguồn: Hands-On K-Means Clustering (do tôi viết).
Một biểu đồ có hình dạng con dao có chiều rộng gần bằng nhau cho chúng ta biết các cụm được cân bằng tốt và có số lượng phiên bản gần như bằng nhau trong mỗi cụm — một trong những giả định quan trọng nhất trong phân cụm K-Means.
Khi các thanh trong hình con dao kéo dài đường đứt nét, các cụm được phân tách rõ ràng — một giả định quan trọng khác trong phân cụm K-Means.
Khi k=3, các cụm được cân bằng và phân tách tốt. Vì vậy, số cụm tối ưu trong ví dụ của chúng tôi là 3.
Các thông số quan trọng nhất của SilhouetteVisualizer bao gồm:
- estimator: ví dụ mô hình K-Means
- colors: chuỗi, một tập hợp các màu được sử dụng cho mỗi hình dạng con dao. ‘yellowbrick’ hoặc một trong các chuỗi bản đồ màu Matplotlib, chẳng hạn như ‘Accent’, ‘Set1’, v.v.
6. Biểu đồ Class Imbalance
Cách sử dụng
Biểu đồ Class Imbalance phát hiện sự mất cân bằng của các lớp trong cột mục tiêu trong bộ dữ liệu phân loại.
Mất cân bằng lớp xảy ra khi một lớp có nhiều phiên bản hơn đáng kể so với lớp kia. Ví dụ: một bộ dữ liệu liên quan đến phát hiện email spam có 9900 trường hợp cho danh mục “Không phải thư rác” và chỉ 100 trường hợp cho danh mục “Thư rác”. Mô hình sẽ không nắm bắt được lớp thiểu số ( danh mục Spam ). Do đó, mô hình sẽ không chính xác trong việc dự đoán tầng lớp thiểu số khi xảy ra sự mất cân bằng trong lớp — Nguồn: 20 sai lầm hàng đầu của Machine Learning và Deep Learning That Secretly Happen Behind the Scene (do tôi viết).
Triển khai với Yellowbrick
Tạo biểu đồ mất cân bằng lớp bằng phương pháp truyền thống rất phức tạp và tốn thời gian. Thay vào đó, chúng ta có thể sử dụng trình hiển thị ClassBalance của Yellowbrick.
Để vẽ biểu đồ mất cân bằng lớp ở Yellowbirck, chúng tôi sẽ sử dụng tập dữ liệu breast_ Cancer (tập dữ liệu phân loại, xem phần Trích dẫn ở cuối).
Đoạn mã sau giải thích cách chúng ta có thể sử dụng trình hiển thị ClassBalance của Yellowbrick để tạo biểu đồ mất cân bằng lớp bằng cách sử dụng bộ dữ liệu breast_ Cancer .

Có hơn 200 trường hợp trong điểm Malignant (Ác tính) và hơn 350 trường hợp trong điểm Benign (Lành tính). Do đó, chúng ta không thể thấy nhiều sự mất cân bằng lớp ở đây mặc dù các thể hiện không được phân bổ đồng đều giữa hai lớp.
Các tham số quan trọng nhất của trình hiển thị ClassBalance bao gồm:
- labels: danh sách, tên của các lớp duy nhất trong cột mục tiêu.
7.Biểu đồ Residuals
Cách sử dụng
Biểu đồ Residuals trong hồi quy tuyến tính được sử dụng để xác định xem phần dư (giá trị quan sát-giá trị dự đoán) có không tương quan (độc lập) hay không bằng cách phân tích phương sai của lỗi trong mô hình hồi quy.
Biểu đồ này được tạo bằng cách vẽ phần dư theo dự đoán. Nếu có bất kỳ loại mẫu nào giữa dự đoán và phần dư, điều đó xác nhận rằng mô hình hồi quy phù hợp không hoàn hảo. Nếu các điểm được phân tán ngẫu nhiên quanh trục x, thì mô hình hồi quy phù hợp với dữ liệu.
Triển khai với Yellowbrick
Tạo biểu đồ phần dư bằng phương pháp truyền thống rất phức tạp và tốn thời gian. Thay vào đó, chúng ta có thể sử dụng trình hiển thị ResidualsPlot của Yellowbrick.
Để vẽ biểu đồ phần dư trong Yellowbirck, chúng tôi sẽ sử dụng bộ dữ liệu Advertising ( Advertising.csv , xem phần Trích dẫn ở cuối).
Đoạn mã sau giải thích cách chúng ta có thể sử dụng trình hiển thị ResidualsPlot của Yellowbrick để tạo biểu đồ phần dư bằng cách sử dụng bộ dữ liệu Advertising.

Phần còn lại | Hình ảnh của tác giả
Chúng ta có thể thấy rõ ràng một số loại mô hình phi tuyến tính giữa dự đoán và phần dư trong đồ thị phần dư. Mô hình hồi quy được trang bị không hoàn hảo, nhưng nó đủ tốt.
Các tham số quan trọng nhất của trình hiển thị ResidualsPlot bao gồm:
- công cụ ước tính: Đây có thể là bất kỳ công cụ hồi quy Scikit-learning nào.
- lịch sử: bool, mặc định
True. Có nên vẽ biểu đồ của phần dư hay không, biểu đồ này được sử dụng để kiểm tra một giả định khác — Phần dư được phân phối chuẩn xấp xỉ với giá trị trung bình bằng 0 và độ lệch chuẩn cố định.
8. Biểu đồ Prediction Error
Cách sử dụng
Biểu đồ lỗi dự đoán trong hồi quy tuyến tính là một phương pháp đồ họa được sử dụng để đánh giá mô hình hồi quy.
Biểu đồ lỗi dự đoán được tạo bằng cách vẽ các dự đoán dựa trên các giá trị mục tiêu thực tế.
Nếu mô hình đưa ra dự đoán rất chính xác, thì các điểm phải nằm trên đường 45 độ. Mặt khác, các điểm được phân tán xung quanh dòng đó.
Triển khai Yellowbrick
Tạo biểu đồ lỗi dự đoán bằng phương pháp truyền thống rất phức tạp và tốn thời gian. Thay vào đó, chúng ta có thể sử dụng trình hiển thị PredictionError của Yellowbrick.
Để vẽ biểu đồ lỗi dự đoán trong Yellowbirck, chúng tôi sẽ sử dụng bộ dữ liệu Quảng cáo ( Advertising.csv , xem phần Trích dẫn ở cuối).
Đoạn mã sau giải thích cách chúng ta có thể sử dụng trình hiển thị PredictionError của Yellowbrick để tạo biểu đồ số dư bằng cách sử dụng bộ dữ liệu Quảng cáo.
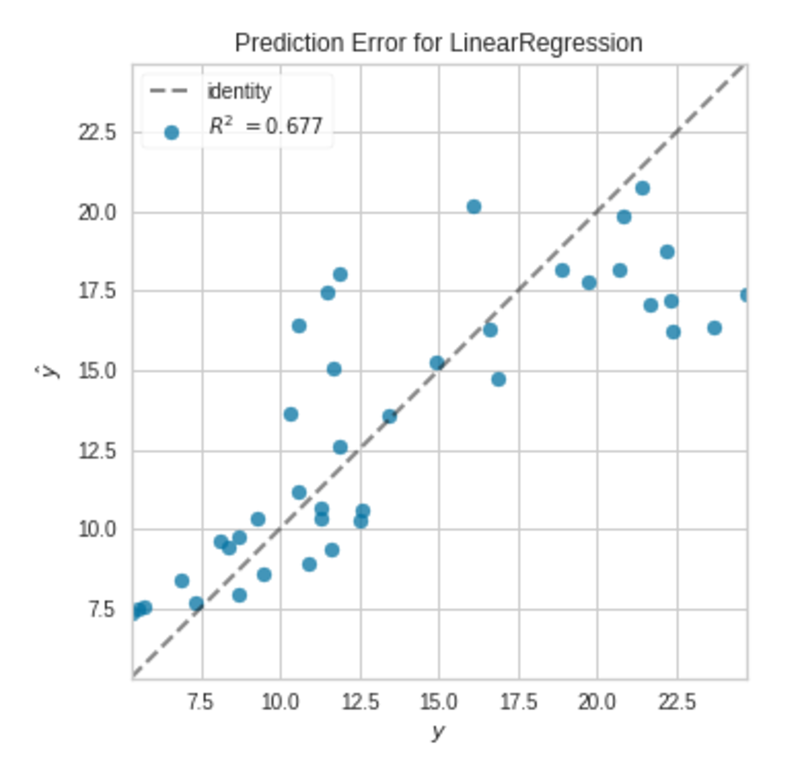
- estimator: Đây có thể là bất kỳ công cụ hồi quy Scikit-learning nào.
- hist: bool, mặc định
True. Có nên vẽ đường 45 độ hay không.
9. Biểu đồ Cook’s Distance
Cách sử dụng
Khoảng cách của Cook đo lường tác động của các phiên bản đối với hồi quy tuyến tính. Các trường hợp có tác động lớn được coi là ngoại lệ. Tập dữ liệu có số lượng ngoại lệ lớn không phù hợp với hồi quy tuyến tính mà không cần xử lý trước. Đơn giản, biểu đồ khoảng cách của Cook được sử dụng để phát hiện các giá trị ngoại lệ trong tập dữ liệu.
Triển khai với Yellowbrick
Tạo biểu đồ khoảng cách của Cook bằng phương pháp truyền thống rất phức tạp và tốn thời gian. Thay vào đó, chúng ta có thể sử dụng trình hiển thị CooksDistance của Yellowbrick.
Để vẽ biểu đồ khoảng cách của Cook ở Yellowbirck, chúng tôi sẽ sử dụng bộ dữ liệu QAdvertising ( Advertising.csv , xem phần Trích dẫn ở cuối).
Đoạn mã sau giải thích cách chúng ta có thể sử dụng trình hiển thị CooksDistance của Yellowbrick để tạo biểu đồ khoảng cách của Cook bằng bộ dữ liệu Advertising.
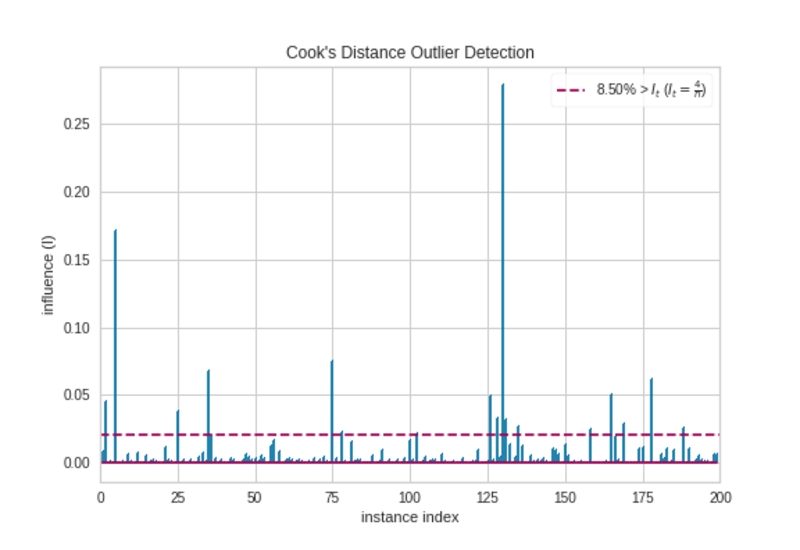
Biểu đồ Cook’s Distance
Có một số quan sát mở rộng đường ngưỡng (ngang màu đỏ). Họ là những người ngoại lệ. Vì vậy, chúng ta nên chuẩn bị dữ liệu trước khi thực hiện bất kỳ mô hình hồi quy nào.
Các thông số quan trọng nhất của trình hiển thị CooksDistance bao gồm:
- draw_threshold: bool, mặc định
True. Có nên vẽ đường ngưỡng hay không.
10. Biểu đồ Feature Importances
Cách sử dụng
Biểu đồ tầm quan trọng của tính năng được sử dụng để chọn các tính năng quan trọng cần thiết tối thiểu để tạo ra một mô hình ML. Vì không phải tất cả các tính năng đều đóng góp như nhau cho mô hình nên chúng tôi có thể xóa các tính năng ít quan trọng hơn khỏi mô hình. Điều đó sẽ làm giảm độ phức tạp của mô hình. Các mô hình đơn giản dễ đào tạo và giải thích.
Biểu đồ tầm quan trọng của tính năng trực quan hóa tầm quan trọng tương đối của từng tính năng.
Triển khai với Yellowbrick
Tạo biểu đồ tầm quan trọng của đối tượng địa lý bằng phương pháp truyền thống rất phức tạp và tốn thời gian. Thay vào đó, chúng ta có thể sử dụng trình hiển thị FeatureImportances của Yellowbrick.
Để vẽ sơ đồ tầm quan trọng của tính năng trong Yellowbirck, chúng tôi sẽ sử dụng bộ dữ liệu breast_ Cancer (xem phần Trích dẫn ở cuối) chứa 30 tính năng.
Đoạn mã sau giải thích cách chúng ta có thể sử dụng trình hiển thị FeatureImportances của Yellowbrick để tạo biểu đồ tầm quan trọng của tính năng bằng cách sử dụng bộ dữ liệu breast_ Cancer.
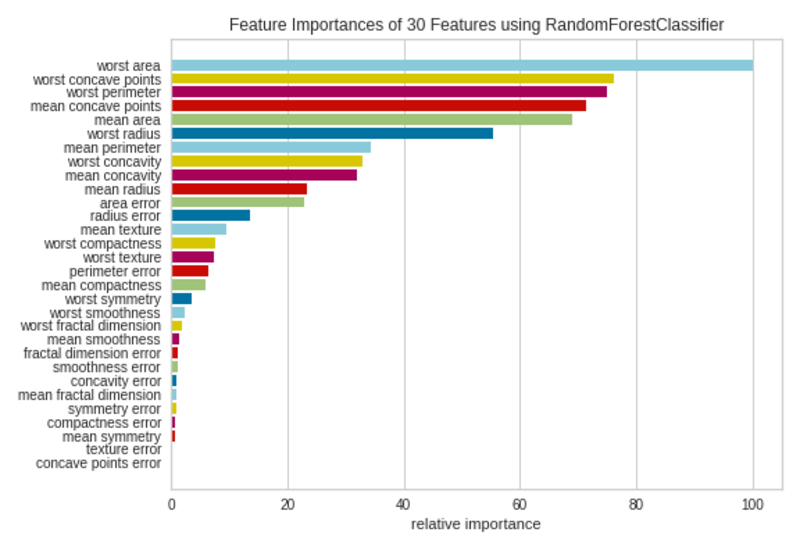
Biểu đồ Cook’s Distance
Không phải tất cả 30 đặc tính trong tập dữ liệu đều đóng góp nhiều cho mô hình. Chúng tôi có thể xóa các tính năng có thanh nhỏ khỏi tập dữ liệu và điều chỉnh lại mô hình với các tính năng đã chọn.
Các tham số quan trọng nhất của trình hiển thị FeatureImportances bao gồm:
- estimator: Bất kỳ công cụ ước tính Scikit-learning nào hỗ trợ
feature_importances_thuộc tính hoặccoef_thuộc tính. - relative: bool, mặc định
True. Có nên biểu thị tầm quan trọng tương đối dưới dạng phần trăm hay không. NếuFalse, điểm số thô của tầm quan trọng của tính năng được hiển thị. - absolute: bool, mặc định
False. Có nên chỉ xem xét độ lớn của các hệ số bằng cách tránh dấu âm hay không.
Tóm tắt về việc sử dụng Trực quan hóa ML
- Biểu đồ thành phần chính: PCA() , Cách sử dụng — Trực quan hóa dữ liệu chiều cao trong biểu đồ phân tán 2D hoặc 3D có thể được sử dụng để xác định các mẫu quan trọng trong dữ liệu chiều cao.
- Đường cong xác thực: ValidationCurve() , Cách sử dụng — Biểu thị ảnh hưởng của một siêu tham số duy nhất đối với tập hợp xác thực và đào tạo.
- Đường cong học tập: LearningCurve() , Cách sử dụng — Phát hiện các điều kiện trang bị thiếu , trang bị quá mức và vừa phải của một mô hình, Xác định sự hội tụ chậm , dao động , dao động với sự phân kỳ và các tình huống hội tụ phù hợp khi tìm tốc độ học tập tối ưu của mạng thần kinh, Cho biết mức độ của chúng tôi mô hình được hưởng lợi từ việc thêm nhiều dữ liệu đào tạo.
- Elbow Plot: KElbowVisualizer() , Cách sử dụng — Chọn số cụm tối ưu trong phân cụm K-Means.
- Silhouette Plot: SilhouetteVisualizer() , Cách sử dụng — Chọn số cụm tối ưu trong phân cụm K-Means, Phát hiện sự mất cân bằng cụm trong phân cụm K-Means.
- Sơ đồ mất cân bằng lớp: ClassBalance() , Cách sử dụng — Phát hiện sự mất cân bằng của các lớp trong cột mục tiêu trong bộ dữ liệu phân loại.
- Residuals Plot: ResidualsPlot() , Cách sử dụng — Xác định xem phần dư (giá trị được quan sát-giá trị dự đoán) có không tương quan (độc lập) hay không bằng cách phân tích phương sai của lỗi trong mô hình hồi quy.
- Biểu đồ lỗi dự đoán: PredictionError() , Cách sử dụng — Một phương pháp đồ họa được sử dụng để đánh giá mô hình hồi quy.
- Sơ đồ khoảng cách của Cook: CooksDistance() , Cách sử dụng — Phát hiện các giá trị ngoại lệ trong tập dữ liệu dựa trên khoảng cách của các phiên bản Cook.
- Biểu đồ tầm quan trọng của tính năng: FeatureImportances() , Cách sử dụng — Chọn các tính năng quan trọng được yêu cầu tối thiểu dựa trên tầm quan trọng tương đối của từng tính năng để tạo ra một mô hình ML.
(Nguồn Rukshan Pramoditha)